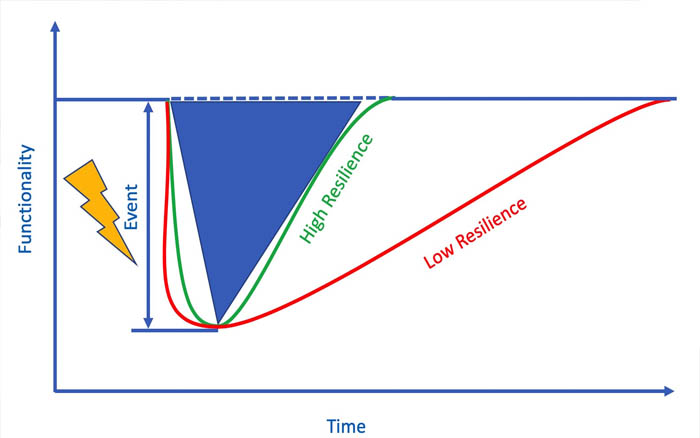
Resiliency Engineering Builds Upon Reliability Engineering
By way of background information, resiliency engineering builds upon reliability engineering, a sub-discipline of systems engineering, which is an interdisciplinary field of engineering and engineering management that focuses upon how to design, analyze, and manage complex engineered systems over their life cycles. Reliability engineering focuses upon the ability of a component, multi-component assemblies, multi-assembly sub-systems, etc. to perform their required functions, within their specified environments, for a specified period of time without failure. While reliability engineering does indeed account for the time to fail for a component, multi-component assemblies, multi-assembly sub-systems, etc. while they are in operation, it does not account for the time necessary pertaining to any repair actions that may take place.
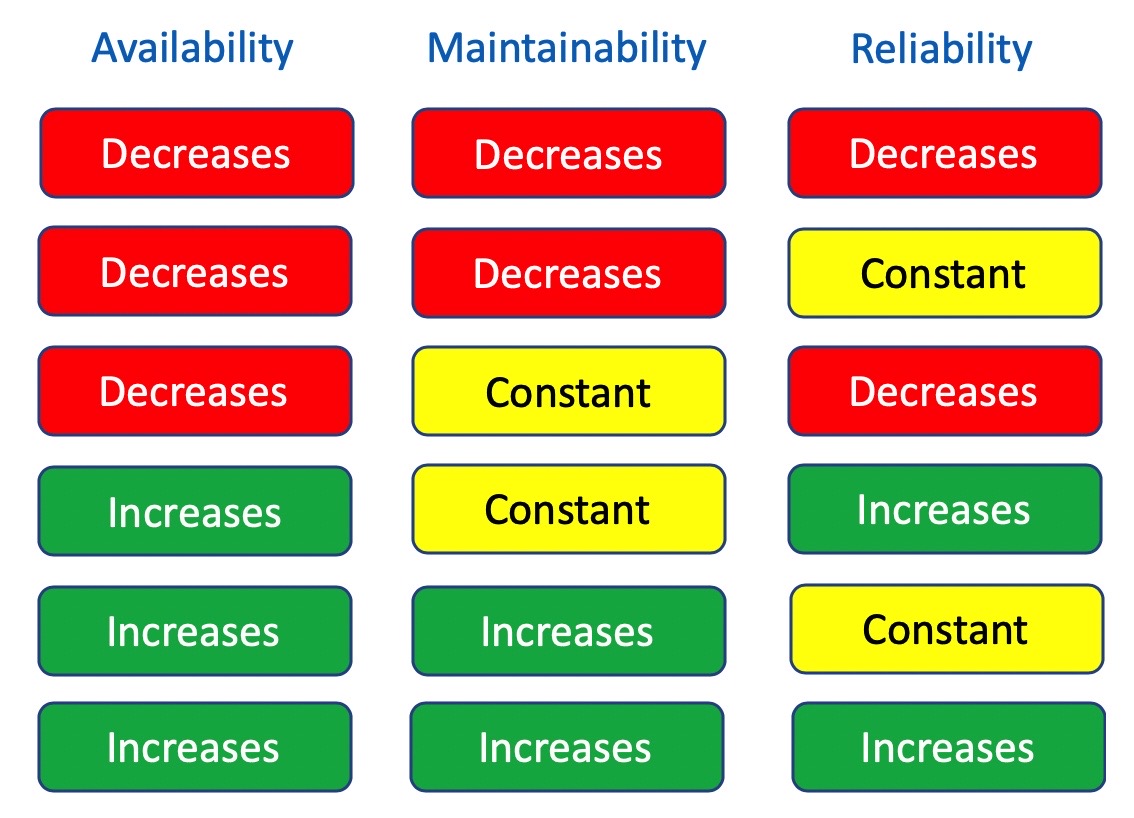
Availability, testability, maintainability, and maintenance are core constituent components of reliability engineering. Typically, reliability engineering looks at preventing failures, such as by changing maintenance management strategies, which are divided into three main classes: corrective maintenance, preventive maintenance, and predictive maintenance. Corrective maintenance allows the involved system to operate until the component, multi-component assemblies, multi-assembly sub-systems, etc. fails, and the item is replaced after the failure occurs. Preventive maintenance is time–based maintenance; it is based upon the notion of performing the service or overhaul after a pre-determined period of time (i.e. optimally close to, but prior to the estimated shelf-life of the component); however, if the maintenance is performed biannually, there could be a six-month blindspot between each maintenance cycle. Predictive maintenance is based upon the core concept that to avoid failure, ongoing estimates of the potential of failure for the various components are performed; this requires condition monitoring.
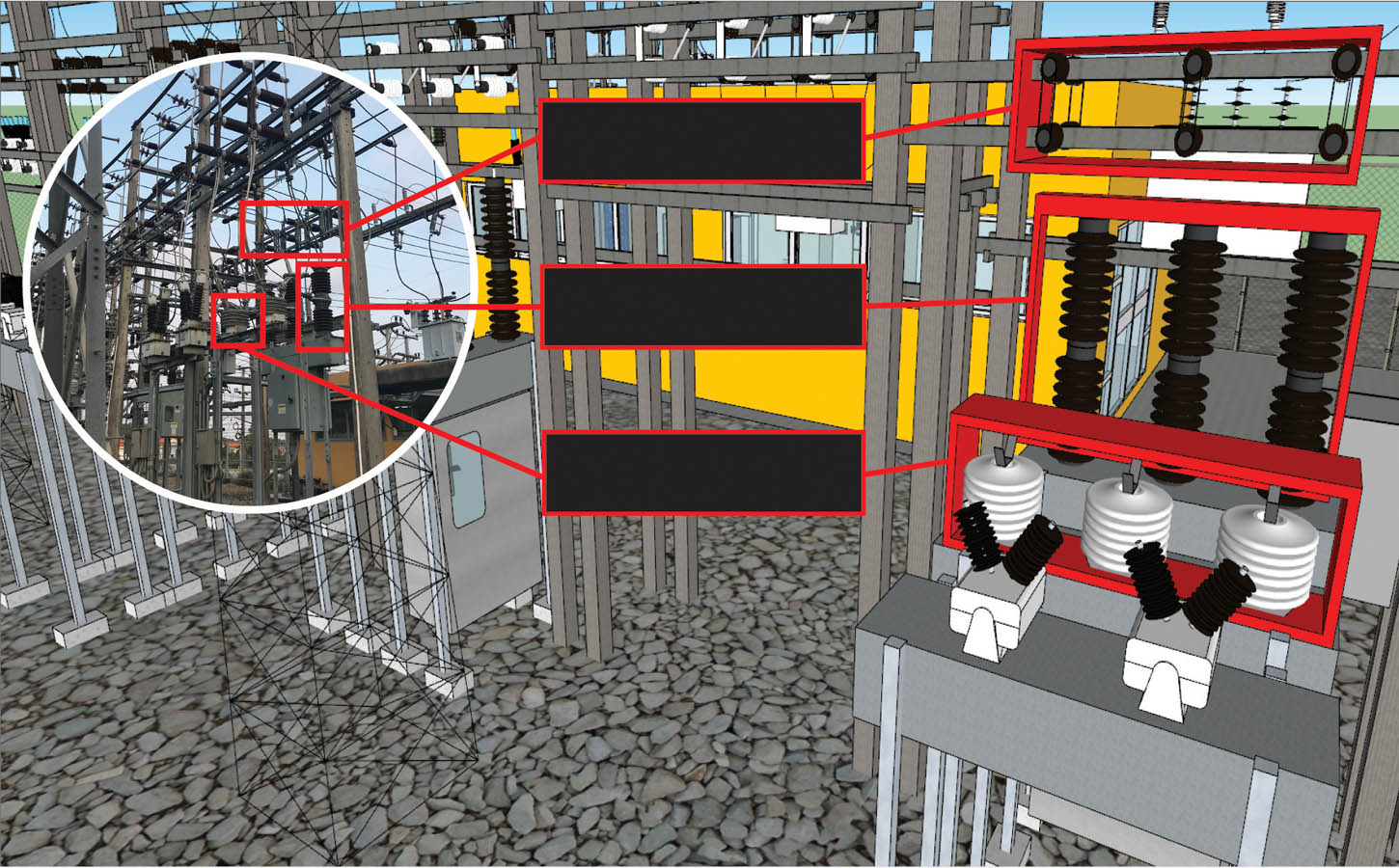
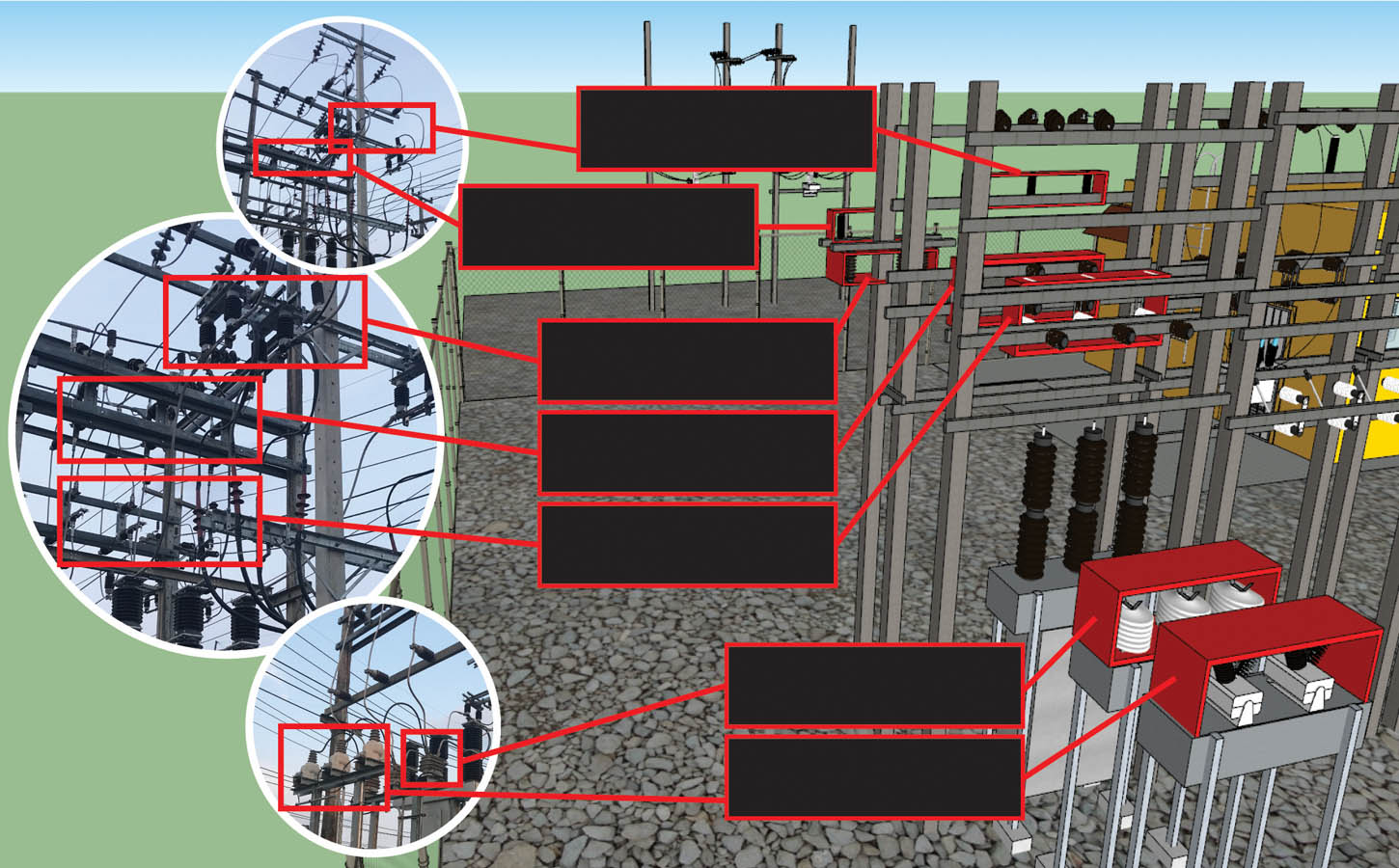
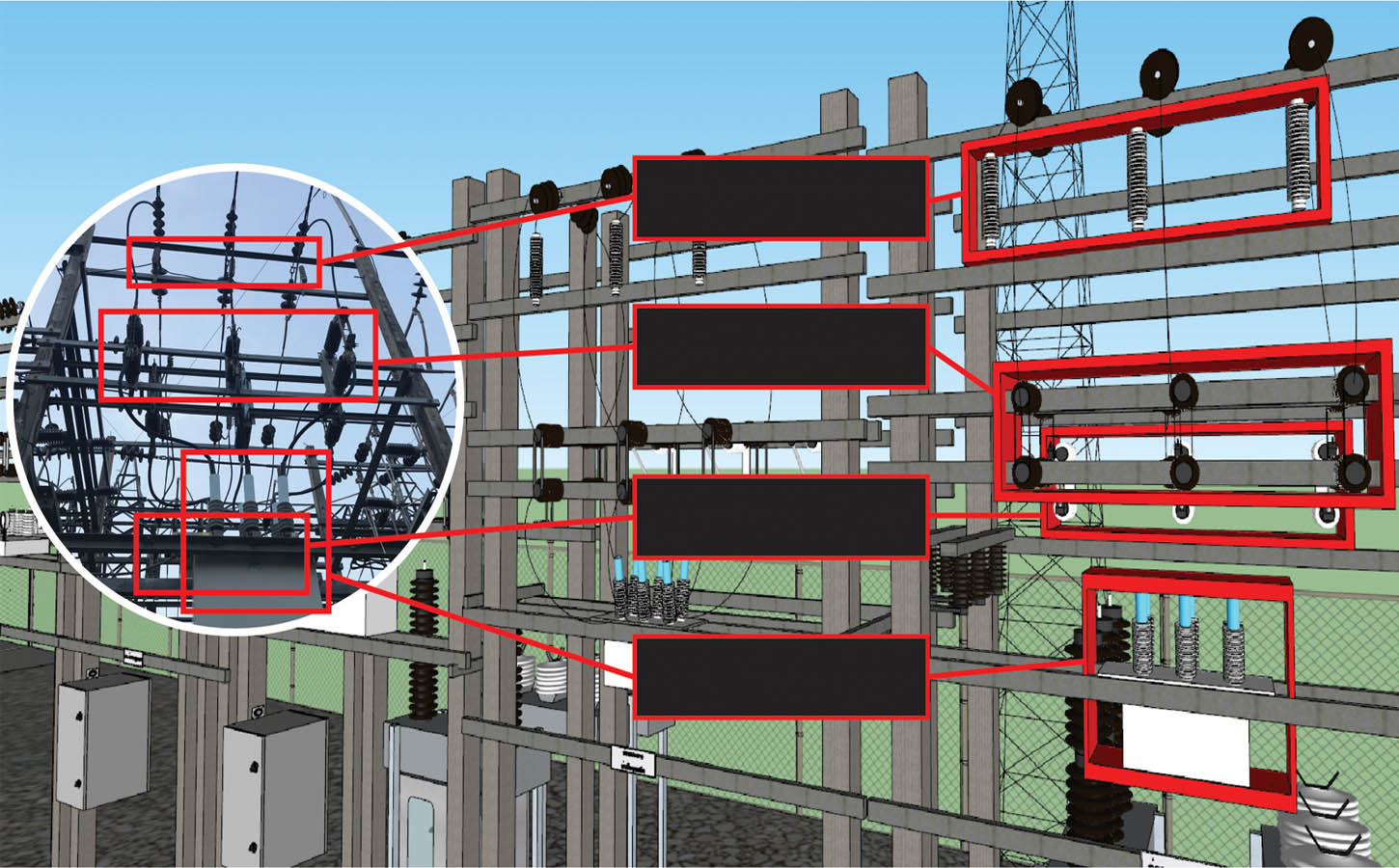
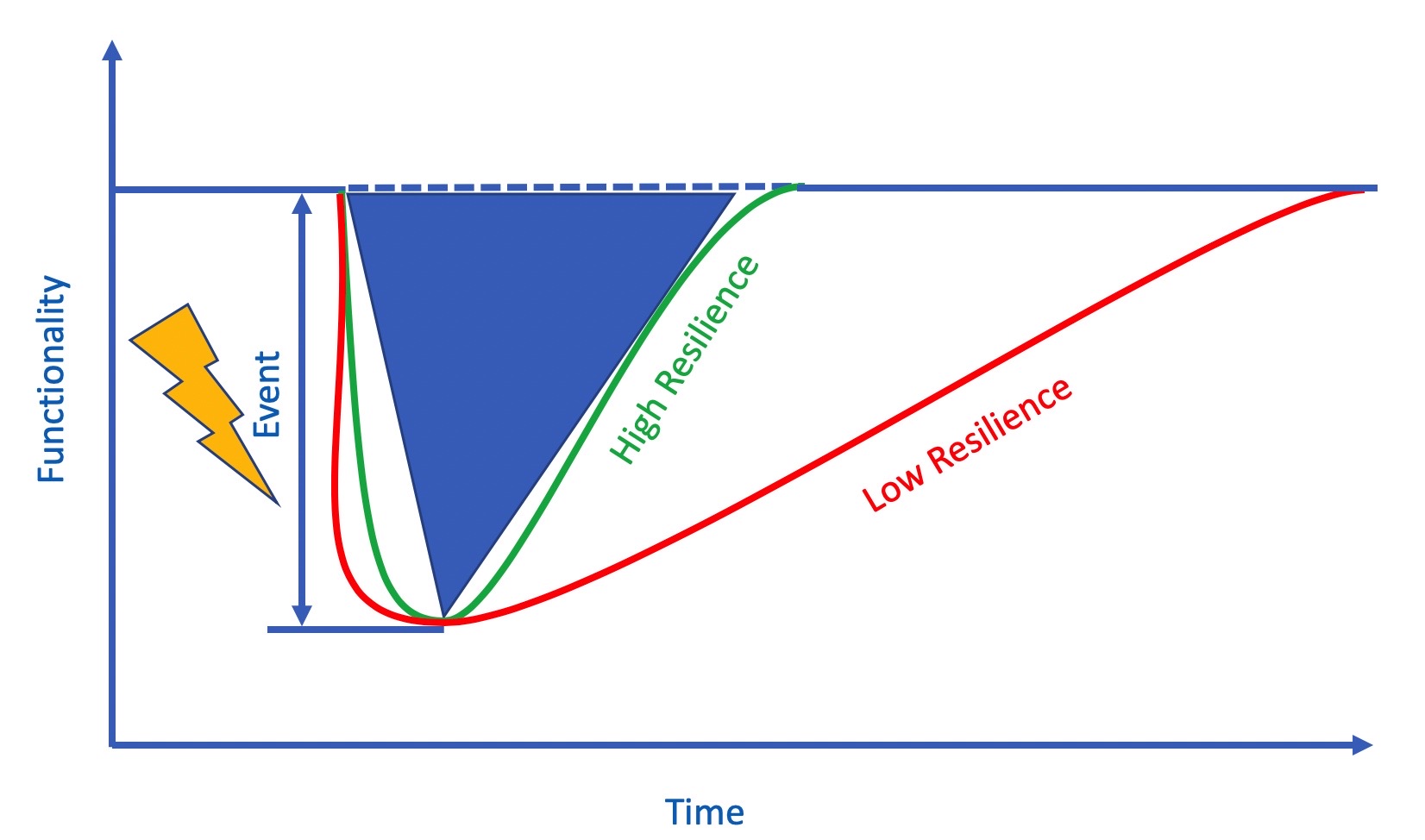
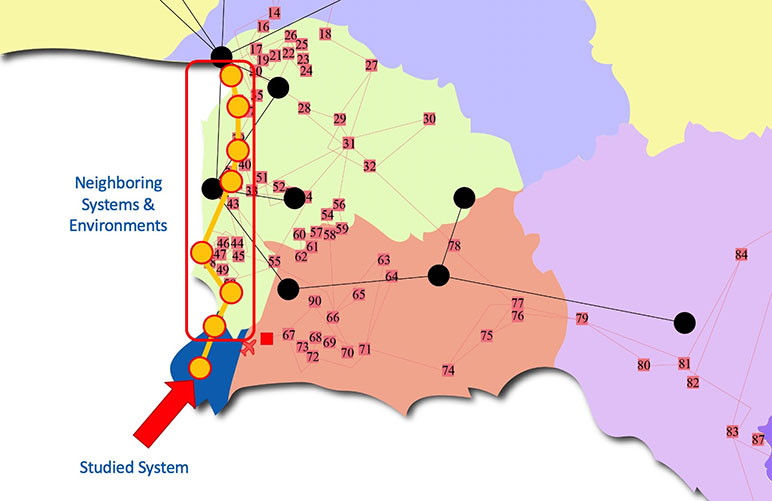
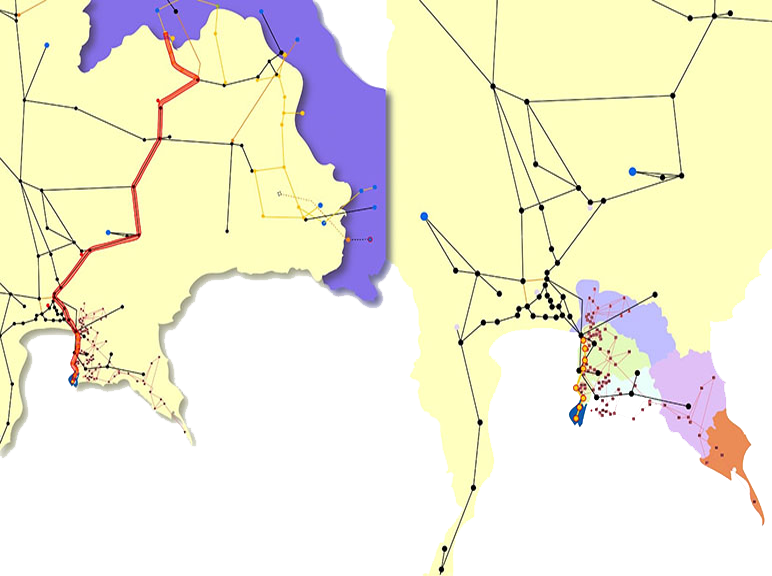
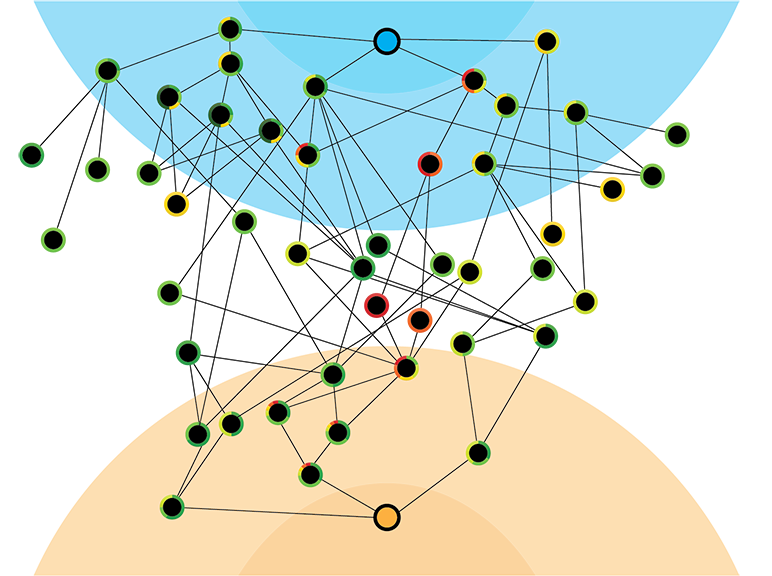
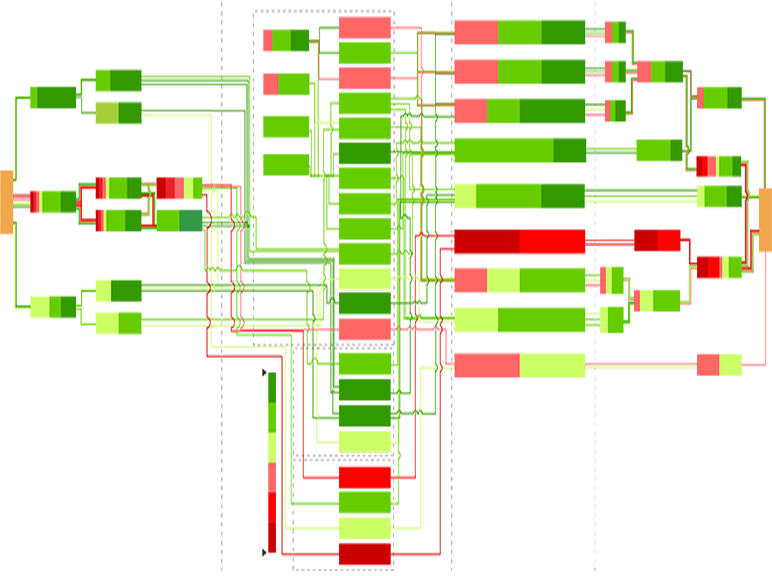
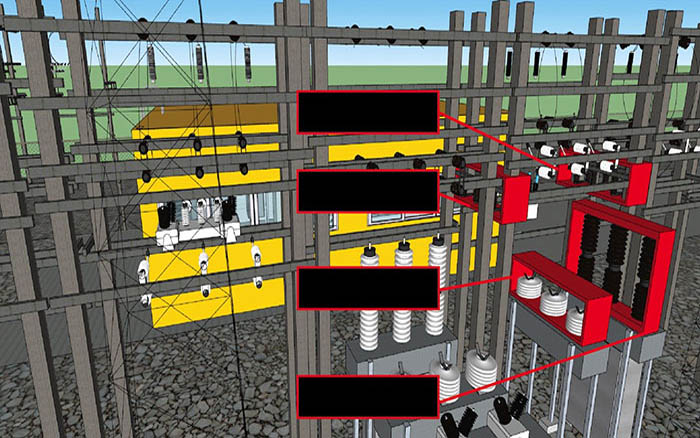
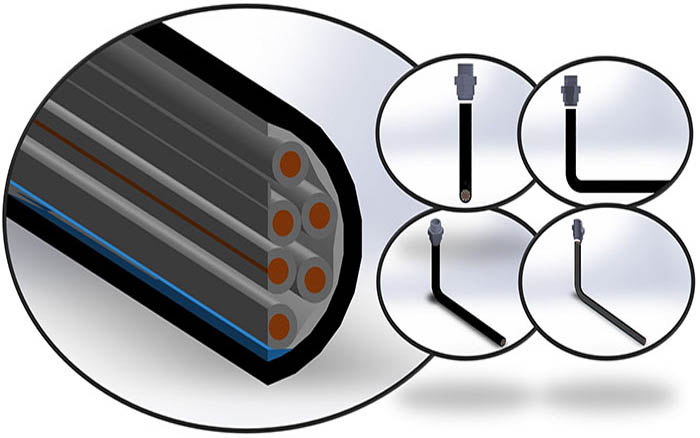
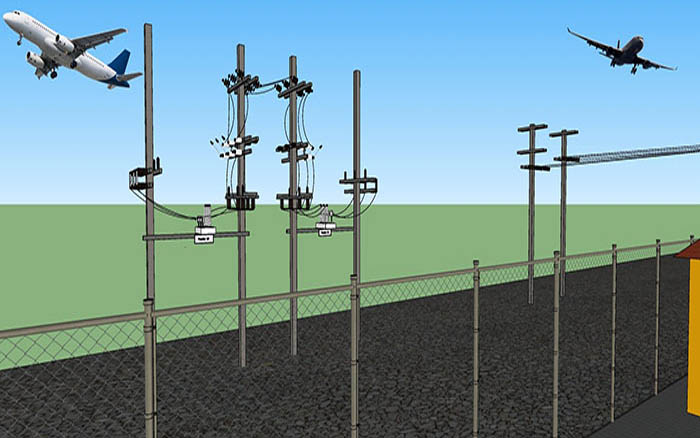
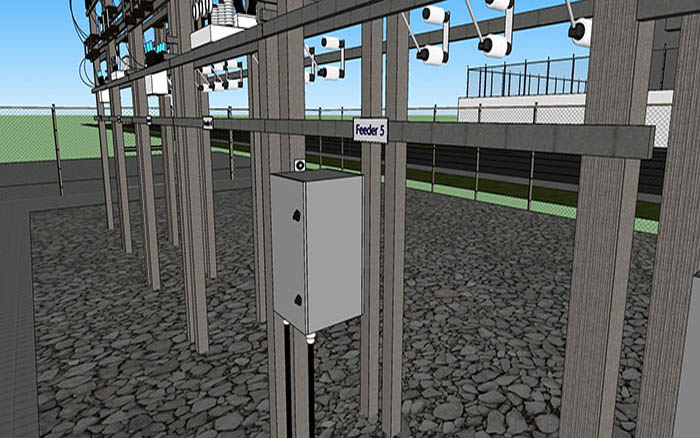
Apart from maintenance, maintainability centers upon the ease and speed with which the involved system can be restored to operational status after a failure occurs. If backup components are not available and need to be ordered, maintainability would be low. Next, testability refers to the ability to run a robust simulation to test a supposition. This requires a robust, granular understanding, such as exemplared in Figures 1a through 1d below, of the various components, multi-component assemblies, multi-assembly sub-systems, and systems (leading up to the involved system of systems) so as to conduct a realistic simulation.